Encourager les pouvoirs locaux (entre autres) à rendre leurs données publiques accessibles à tous (principe de l’open data) est certes une bonne chose. Collecter des données, enrichir ainsi son stock potentiel de connaissances et de prise de décision, c’est aussi une bonne chose. Encore faut-il savoir quoi faire et comment “exploiter” ces données…
{kind=link}
Ce constat – cette évidence – est le point de départ d’un projet de développement porté par Jérôme Fink, un jeune chercheur de l’UNamur, qu’il espère pouvoir poursuivre jusqu’à aboutir à une appli ou solution concrète.
Au départ, son idée, dans le cadre de ses travaux de recherche à l’UNamur, était de se focaliser sur l’analyse des publications faites sur les réseaux sociaux (analyse d’opinion, de “sentiments”…). Ce périmètre d’analyse donnera d’ailleurs lieu, à court terme, à une recherche universitaire sur le thème de l’“opinion mining” sur réseaux sociaux.
Mais, entre-temps, Jérôme Fink a quelque peu fait évoluer son idée pour inclure dans son analyse des données venant d’autres sources – plates-formes de participation citoyenne, consultations populaires, forums Internet… L’opportunité de s’engager dans cette voie lui a été donnée par le récent hackathon Citizens of Wallonia, organisé par FuturoCité, auquel il a participé, et par la mise à disposition, pendant les trois jours de ce hackathon, des données récoltées par la Ville de Liège à l’occasion de sa campagne participative Réinventons Liège.
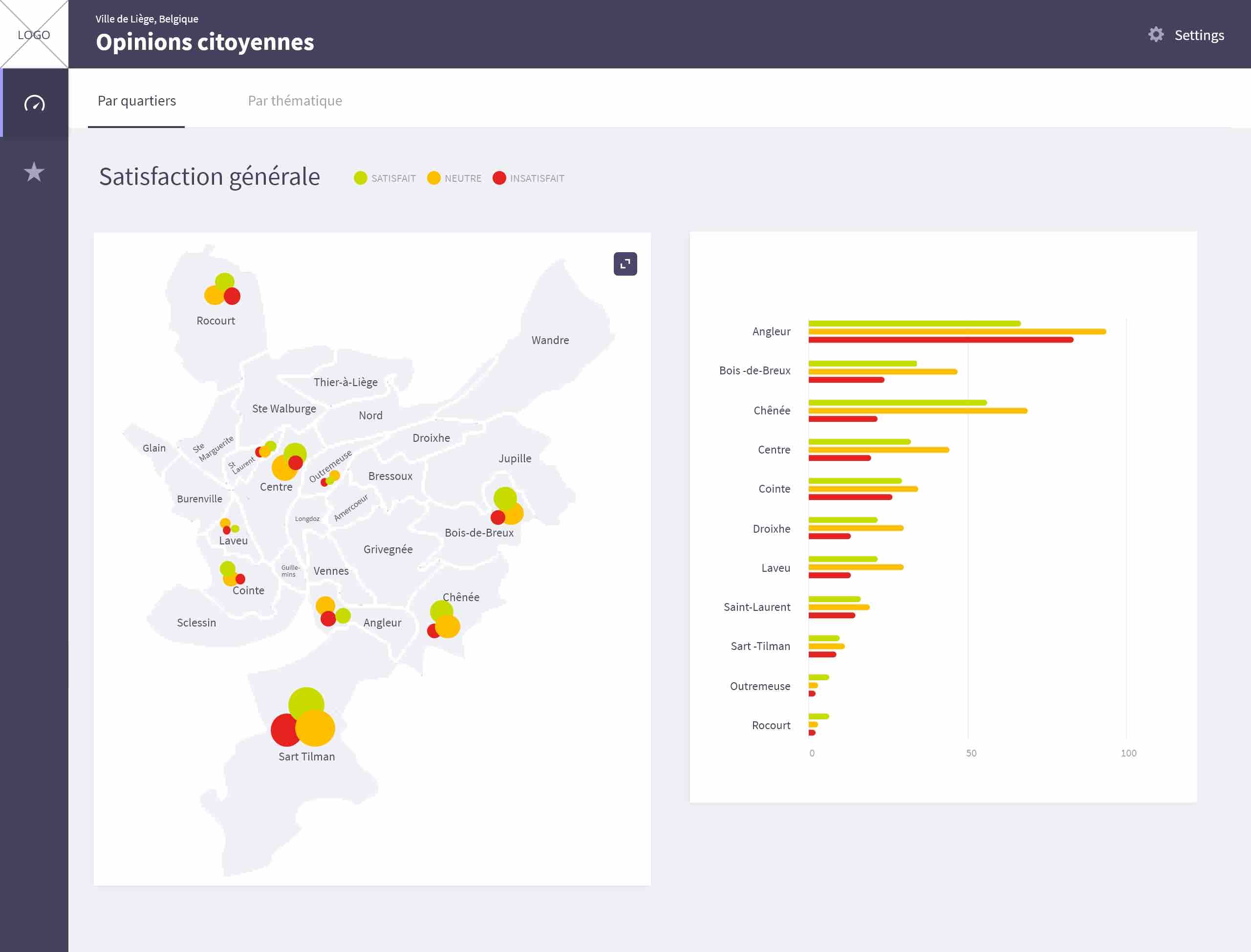
“L’idée du projet que j’ai proposé est d’enrichir les données de participation citoyenne récoltées par exemple par le biais de plates-formes [du genre CitizenLab ou Fluicity]. Dans le cas de la campagne Réinventons Liège, la Ville a recueilli près de 1.000 commentaires [pour être exact, 983 idées ont été récoltées, après participation de 1.568 personnes – en-ligne ou lors d’ateliers présentiels].
L’essentiel des contributions de citoyens, dans ce genre de cas, prend la forme de textes. Le problème pour les autorités locales est d’en faire une analyse pertinente pour sélectionner par exemple les meilleurs avis ou les propositions et réactions pertinentes.”
Visualiser de manière éloquente les résultats de mécanismes de “clustering” automatique sur base des contenus de contributions citoyennes…
{kind=link}
D’où l’idée d’appliquer des techniques d’analyse textuelle (text mining, text clustering…) et d’“enrichir” ces informations brutes en dégageant non seulement des tendances mais en créant des indicateurs et en faisant s’afficher automatiquement les résultats de l’analyse (par algorithmes, avec ou sans intervention humaine) sous des formes visuelles qui soient plus “parlantes” pour les décideurs publics.
Bien au-delà donc de ce qu’on appelle habituellement l’analyse de “sentiments”: citoyen fâché, approbateur, bougon ou râleur…
Détection et analyse d’opinions
Dans le cadre de l’analyse des résultats de la campagne Réinventons Liège, il aurait sans doute été intéressant de croiser ces données avec d’autres, piochées par exemple sur les réseaux sociaux. Mais Jérôme Fink dit avoir à nouveau fait le constat que l’“ombre de l’épisode Cambridge Analytica plane encore sur ce qu’il est possible de faire. Les coaches présents au hackathon m’avaient déjà mis en garde contre l’usage excessif de données citoyennes. Quand j’ai voulu exploiter l’API proposée par Twitter, j’ai été invité à remplir le petit questionnaire prévu lors de ce genre de requête. Or, l’une des questions est: “les données seront-elles utilisées par des personnes du monde politique?” La réponse, dans le cadre du projet, étant positive [rappelons que le but est de permettre aux décideurs publics locaux de prendre de meilleures décisions], l’accès aux données Twitter m’a été refusé! C’est là un fait dont il faut avoir conscience quand on veut travailler sur des open data…”
Résultat: il a restreint son champ d’analyse aux seules données collectées via la plate-forme de participation citoyenne mise en oeuvre par CitizenLab.
Des outils standard et des algos perso
Pour jeter les bases de sa solution d’analyse de sentiments sur données participatives, Jérôme Fink a fait appel à la fois à des outils d’analyse de texte préexistants (IBM, Microsoft ou encore Amazon, notamment, proposent des API) et à des algorithmes qu’il a lui-même développés. “Les API disponibles permettent déjà d’effectuer un travail préliminaire pour dégager des “sentiments” de textes bruts. Du genre personne fâchée ou non, ou encore pour identifier les lieux géographiques cités.”
Mais cela ne suffit évidemment pas.
Jérôme Fink (UNamur): “Le problème pour les autorités locales est de faire une analyse pertinente des contributions citoyennes pour sélectionner par exemple les meilleurs avis ou les propositions et réactions pertinentes.”
{kind=link}
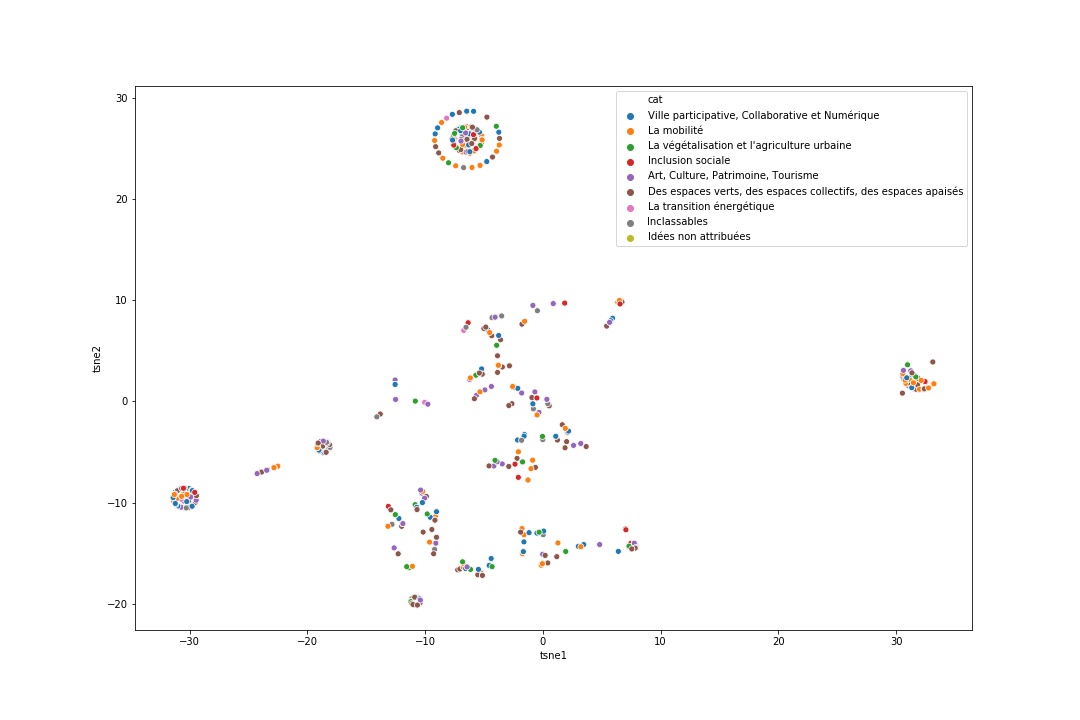
Il a donc eu recours à des techniques de text clustering afin de rapprocher des opinions proches et, via transformation en vecteurs, leur a attribué des valeurs et pondérations et a généré une visualisation de groupements logiques.
Les techniques mises en oeuvre permettent notamment de créer des “clusters” par catégorie thématique (mobilité, propreté…) mais aussi de faire émerger des ressemblances ou proximités d’opinion transcendant les catégories. “Il est possible d’extraire de nouvelles catégories pour mieux identifier des opinions et porter ainsi un autre regard sur les avis collectés.”
Exemple? Les initiatives ou situations de la vie dans l’espace public ou dans la vie quotidienne qui sont ressenties comme étant sympas, problématiques… Ou des choses disparates qui suscitent un sentiment auquel est associée l’étiquette “disparition” – “cinémas, poubelles, petites boutiques qui sont moins présents dans l’espace public, services qui ne sont plus disponibles ou sont plus difficiles à trouver…”
Jérôme Fink a développé lui-même les algorithmes qui ont permis de dégager automatiquement ces ressemblances ou ces proximités de “sentiments” et de générer ainsi diverses catégories (thématiques): “Les méthodes de clustering existent et il est devenu très facile désormais de créer soi-même des algorithmes, en Python pour ce qui me concerne, en l’espace de quelques heures.”
Mais la “machine” n’en est pas pour autant efficace ou toujours pertinente. “Dix catégories ont été générées au départ par l’ordinateur, dont cinq étaient réellement pertinentes. On a par ailleurs vu émerger de nouvelles catégories intéressantes – telles que disparitions, arts, monuments – ces deux dernières se mélangeant un peu d’ailleurs… D’autres catégories, par contre, étaient plus douteuses – comme ‘propice’ ou ‘pilote’.”
La jugeote humaine demeure donc nécessaire…
Pour rendre les résultats plus explicites et aisément exploitables par les destinataires visés – rappelons qu’il s’agit en priorité des décideurs publics -, la UI (user interface) designeuse de l’équipe de Jérôme Fink a imaginé différents types de représentation et de visualisation des données. “Au-delà de la projection des résultats, regroupés, sur une carte ou dans un espace spécifique, il faut imaginer une représentation qui suscite des questions, qui donne envie d’explorer les données. Il faut aller au-delà de l’analyse pour susciter la réflexion.”
Le projet ébauché lors du hackathon Citizens of Wallonia a-t-il de l’avenir? Encore trop tôt pour le dire mais les membres de l’équipe éphémère ont exprimé leur désir de rester en contact. “Nous aimerions continuer à développer la solution. Les membres du jury [soit dit en passant, le projet a récolté deux récompenses – Prix Open Data et Prix Intelligence artificielle] nous ont d’ailleurs confirmé que la demande existe du côté des communes.”
Le hackathon se déroulait à Liège et la Ville y avait délégué quelques grosses pointures pour la remise des récompenses. Pour l’heure toutefois, même si les données sur lesquelles l’équipe a travaillé sont celles de la campagne Réinventons Liège, aucun contact concret pour envisager une suite éventuelle n’a été noué. Mais ce n’est peut-être que partie remise.
Jérôme Fink lui-même, même s’il est Liégeois d’origine, étudie désormais à Namur et indique qu’il sera sans doute plus facile pour lui de regarder du côté de la Ville de Namur pour un intérêt éventuel pour son projet. Peut-être aura-t-on l’occasion d’en reparler…
Jérôme Fink poursuit actuellement un master en data sciences à l’université de Namur. Son intérêt, “une véritable passion”, pour l’analyse des données et l’intelligence artificielle est relativement récent (il s’est lancé dans des études orientées informatiques après avoir travaillé cinq ans comme… pompiste).
Détenteur d’un bac en informatique décroché à la Haute Ecole de la Province de Liège, il dit vouloir continuer dans cette voie de la “science des données”. La faculté d’informatique de l’UNamur l’a d’ailleurs embrigadé pour travailler sur le développement d’algorithmes traduisant automatiquement le langage des signes en français. Et ce, dans le cadre du projet de dictionnaire bilingue contextuel français-langue des signes, qu’il mène en collaboration avec des linguistes de l’université.
Lors du hackathon, Jérôme Fink a notamment fait équipe avec une UI designeuse et un agent communal de Fléron.
Découvrez-nous sur Facebook
Suivez-nous sur Twitter
Retrouvez-nous sur LinkedIn
Régional-IT est affilié au portail d’infos Tribu Médias.