Récemment, la société néolouvaniste Eura Nova, spécialisée dans la science des données et l’intelligence artificielle (recherche et prestation de services), avait organisé un hackathon au cours duquel les participants (une septantaine d’ingénieurs et d’étudiants en sciences des données) étaient invités à “construire une solution innovante destinée à leurrer un algorithme d’intelligence artificielle”.
{kind=link}
Pourquoi diable organiser un tel exercice? Leurrer une intelligence artificielle suscite d’emblée une immense inquiétude. Non seulement, il arrive déjà à des algorithmes, mal alimentés, mal entraînés, biaisés, de se tromper d’eux-mêmes – l’exemple le plus souvent cité est celui de cette “intelligence” artificielle qui voit une banane… là où on lui présente l’image d’un chat!
Ensuite, le manque de transparence sur les rouages et les “raisonnements” ou déductions d’une IA inquiètent déjà bien des observateurs. Et on parle maintenant de tromper volontairement cette IA?
Et les vainqueurs sont…
Plus de 70 ans jeunes, déjà actifs comme ingénieurs en sciences des données ou encore aux études (venant de 18 universités d’Europe et d’Afrique du Nord), ont donc rivalisé d’imagination lors de ce hackathon NovHack, organisé à l’intiative d’Eura Nova. L’équipe gagnante était composée de trois étudiants à l’ULB (Miro-Manuel Matagne, Rania Charkaoui et Yassine Ben Yaghlane) et de Hassan Mkhallati, étudiant à l’Ecole Polytechnique de Paris.
En fait, le but est de chercher à concevoir ces algorithmes de telle sorte qu’ils soient justement plus efficaces, performants et valides en comprenant ce qui les induit en erreur. Du virtuous hacking si vous préférez.
L’occasion de ce hackathon était belle pour nous de nous pencher sur cette technique que l’on désigne sous l’appellation d’“attaque adverse”. Une technique qui est donc aujourd’hui utilisée à des fins méritoires pour améliorer les réseaux de neurones (artificiels) mais qui ouvre potentiellement une nouvelle brèche et opportunité pour les hackers. De quoi s’agit-il?
Damien Fourrure, data scientist chez Euro Nova, spécialisé en vision numérique, nous dresse le contexte: “Dans le domaine de l’intelligence artificielle, et plus particulièrement de l’apprentissage automatique, des algorithmes sont entraînés à résoudre des tâches spécifiques. Par exemple, en classification d’image, l’objectif est de prédire l’objet présent dans cette dernière.
Ces dernières années, les classifieurs sont devenus de plus en plus performants, notamment grâce à l’utilisation de réseaux de neurones artificiels. Néanmoins, ces derniers ne sont pas parfaits et peuvent commettre des erreurs.
Une attaque adverse consiste à exploiter les faiblesses des classifieurs afin de les tromper. Dans le cas de la classification d’image, cela consiste à modifier légèrement une image, de façon imperceptible à l’œil humain, mais de manière à ce que le réseau de neurones attaqué se trompe complètement dans sa prédiction.”
Il cite en exemple l’image d’un chat – image correctement classée préalablement par le réseau de neurones. En la modifiant légèrement, par ajout de “bruit”, il est possible et même hyper-facile d’induire l’algorithme en erreur, l’amenant à identifier par exemple… une voiture de sport – voir l’illustration ci-dessous. “Cela revient en quelque sorte à créer une illusion d’optique pour l’intelligence artificielle.”
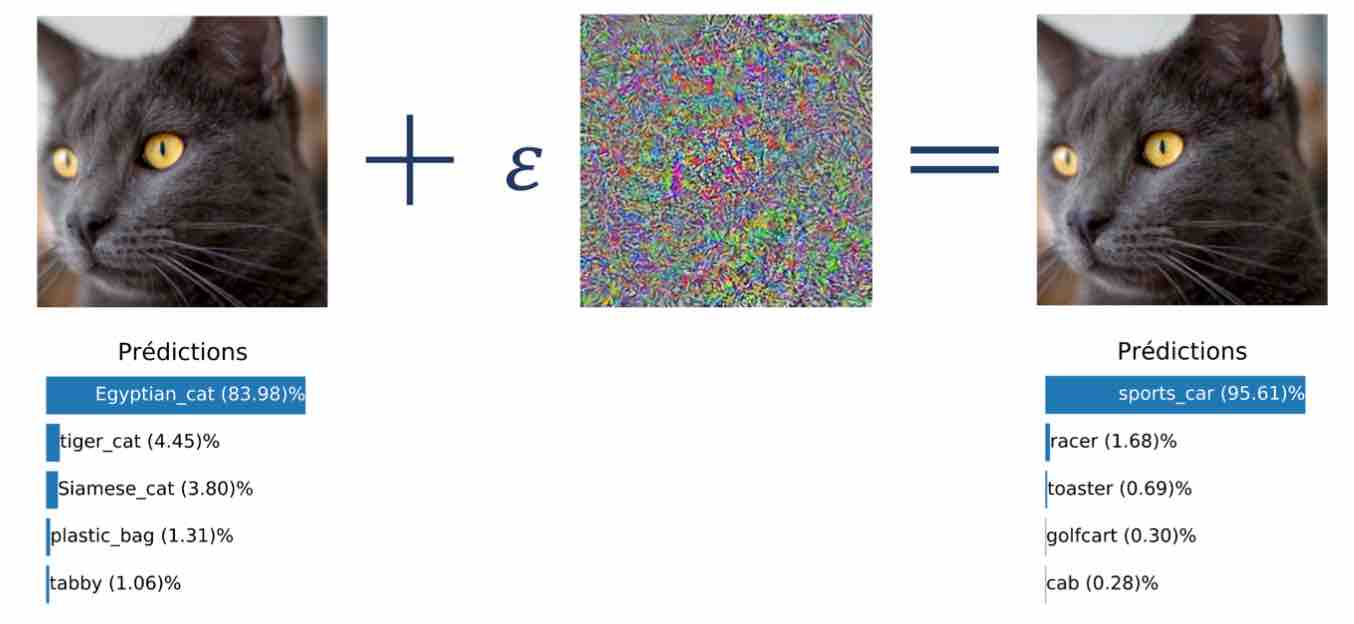{kind=link}
La dose de “bruit” à insérer peut être minime. Il a en effet été démontré que l’altération, l’ajout ou le retrait d’un ou de quelques pixels peut avoir des conséquences inattendues. Et ce qui vaut pour la reconnaissance d’image vaut également par exemple pour l’identification vocale…
Autre technique déjà utilisée par les hackers: l’“empoisonnement” des données. Une personne extérieure prend le contrôle d’une partie des données d’apprentissage, la modifie, pollue, dénature pour tromper le modèle d’apprentissage et induire des dysfonctionnements pervers.
La main de l’homme ou le fait de la machine?
Ces “détournements” – volontaires – sont-ils, dans l’état actuel des choses, le fait d’humains ou… de programmes d’IA? La pratique risque-t-elle de prendre de l’ampleur et, surtout, viser des finalités malveillantes?
Comme le dit Damien Fourrure, “une attaque adverse correspond, en quelque sorte, à hacker le réseau de neurones artificiel. Un attaquant va s’en prendre à un réseau en perturbant soigneusement une image donnée, en entrée, de telle sorte que le réseau produise une réponse incorrecte et se trompe dans sa classification.”
Le fait-il “manuellement” ou se sert-il d’outils automatiques? “À l’instar d’un hacker, le data scientist a à sa disposition plusieurs algorithmes permettant d’attaquer le réseau de neurones. Certains de ces algorithmes étant eux même basés sur des réseaux de neurones artificiels.”
Deux types d’attaque
“On distingue généralement deux types d’attaque adverse. Une attaque appelée “white box” où l’attaquant a directement accès au réseau de neurones et peut donc, en quelque sorte, se brancher directement sur le réseau et analyser les différentes réponses de ce dernier.
Dans le second type d’attaque, appelée “black box”, l’attaquant n’a pas d’accès direct au réseau, mais uniquement à ses prédictions. Cette configuration est plus compliquée mais il existe maintenant de nombreuses méthodes permettant de hacker le réseau.”
Des risques à l’horizon
Cet attaquant, dans un scénario “vertueux”, est par exemple un data scientist qui est armé d’intentions louables. “Actuellement, les attaques adverses ne sont utilisées que par la communauté scientifique. Elles sont principalement étudiées dans une optique d’amélioration des réseaux de neurones artificiels, car elles permettent de mieux comprendre le fonctionnement de ces derniers et de les rendre toujours plus performants, plus robustes face à ce type d’attaques. Pour cela, il est par exemple possible d’entraîner un second réseau de neurones à détecter si une image a été modifiée ou non. Malheureusement, ce second réseau est lui aussi sensible aux attaques adverses. Le meilleur moyen pour se protéger de ce genre d’attaque reste donc de cacher au maximum le réseau afin de rendre les attaques le plus difficile possible.”
Mais, évidemment, les choses pourraient changer rapidement et les objectifs louables faire place à des pratiques résolument malveillantes.
{kind=link}
“Les réseaux de neurones artificiels étant de plus en plus présents dans notre monde, les attaques adverses ont aussi un impact majeur sur la sécurité des systèmes qui nous entourent. À notre connaissance, aucune attaque malveillante n’a encore eu lieu, mais il est important d’avoir conscience de la vulnérabilité des réseaux de neurones.
Plusieurs équipes scientifiques ont tiré la sonnette d’alarme. Par exemple, dans le cas des véhicules autonomes, une équipe du Tencent Keen Security Lab a réussi à faire rouler une Tesla Model S en sens inverse, en la forçant à changer de voie de circulation à l’aide de trois petits patchs positionnés stratégiquement sur la route. [Source: Tencent Keen Security Lab]
D’autres cas d’erreur touchant les véhicules autonomes ont été largement documentés. Et il suffit parfois de bien peu de chose. Par exemple, un graffiti ou une feuille morte malencontreusement collée sur un panneau de signalisation qui fait passer une limitation de vitesse de 30 km/h à 90 km/h… Il suffit parfois d’un simple reflet lumineux pour induire l’“intelligence” en erreur.”
Damien Fourrure (Eura Nova): “un véritable jeu du chat et de la souris entre les scientifiques cherchant à améliorer l’intelligence artificielle de demain, et ceux qui cherchent à la tromper.”
“Un autre exemple s’inscrit dans le cadre des outils de reconnaissance faciale. Une équipe scientifique a réussi à construire des lunettes qui permettent de tromper les outils de reconnaissance faciale et même de se faire passer pour un autre aux yeux des réseaux de neurones.” Source: “Accessorize to a crime: real and stealthy attacks on state-of-the-art face recognition”
Ici aussi, il ne faut pas sortir de bazooka pour réussir à tromper le réseau de neurones. De simples lunettes imprimées en 2D suffisent. Les “couacs” qui ont ainsi été provoqués poussent évidemment les concepteurs à revoir leur copie et à renforcer les algorithmes qu’ils utilisent – on a par exemple vu les fournisseurs spécialisés en reconnaissance d’image retravailler leurs solutions pour faire en sorte que les algorithmes demeurent efficaces même en présence d’une personne masquée pour cause de Covid…
Il n’en reste pas moins, comme le souligne Damien Fourrure que “ces exemples, parmi tant d’autres, démontrent une véritable faiblesse de l’intelligence artificielle. Heureusement, les scientifiques travaillent actuellement à rendre les réseaux de neurones de moins en moins sensibles aux attaques adverses, mais aussi… à rendre les attaques adverses plus performantes.
Cela crée, à l’instar des hackers sur le réseau Internet, un véritable jeu du chat et de la souris entre les scientifiques cherchant à améliorer l’intelligence artificielle de demain et ceux qui cherchent à la tromper.”
D’où cette question: les cursus (chez nous) s’adaptent-ils pour prendre en compte ces techniques, soit pour apprendre à les identifier et contrecarrer, soit pour être capable d’en créer? “La recherche avance constamment et les attaques adverses sont encore un sujet de pointe peu abordé dans les universités”.
C’est d’ailleurs, souligne Eura Nova, la raison pour laquelle elle a eu l’idée de ce hackathon: “on souhaitait que les étudiants se retrouvent face à une problématique qu’ils ne connaissent pas ou peu, afin de les challenger sur leur capacité à explorer de nouvelles techniques, mais aussi de les sensibiliser aux vulnérabilités de l’intelligence artificielle.”
Découvrez-nous sur Facebook
Suivez-nous sur Twitter
Retrouvez-nous sur LinkedIn
Régional-IT est affilié au portail d’infos Tribu Médias.