L’infrastructure que constitue actuellement NRB et qu’elle gèrera et exploitera pour les besoins de Wallonia Big Data est, pour l’essentiel, d’origine IBM.
{kind=link}
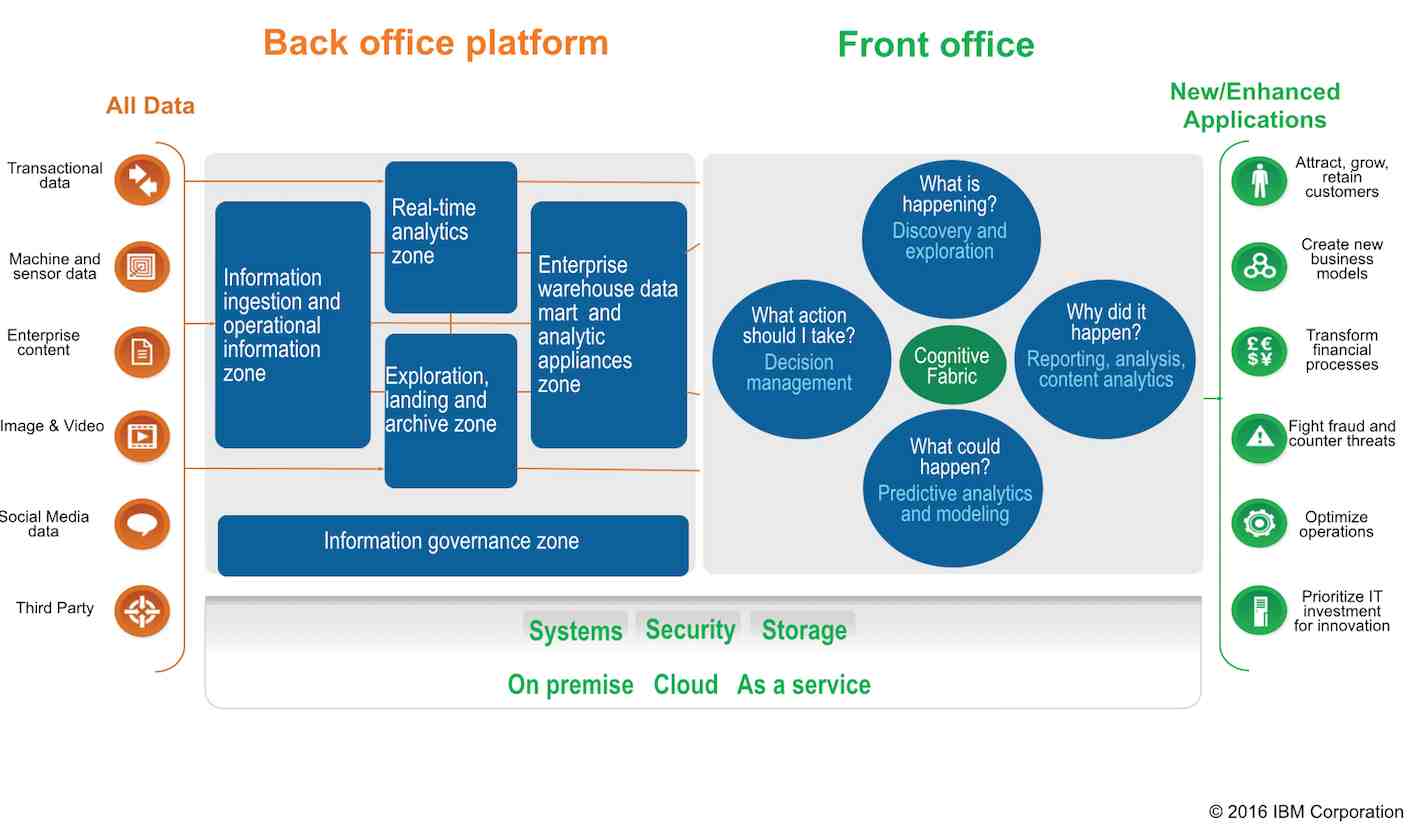
Le matériel (serveurs, systèmes de stockage) mais aussi une panoplie d’outils logiciels, en ce compris d’origine open source mais encapsulés, viennent de Big Blue. Depuis les clusters Hadoop ou les systèmes dédiés PureData (analytique) jusqu’au Big Data Framework (évaluation du stade et du modèle de maturité big data), en passant par les logiciels PMQ (Predictive Maintenance and Quality), solution de suivi en temps réel de multiples sources de données en vue d’anticiper des défaillances d’équipements ou encore les outils de gouvernance.
Les premiers systèmes ont été réceptionnés mais la phase de construction et de mise en oeuvre est loin d’être terminée même si, comme le signale NRB, “certains composants pourraient déjà être mis à contribution.”
L’infrastructure se prépare
Au-delà de l’activation des équipements et des logiciels, c’est surtout le dimensionnement et la configuration de l’ensemble qui prendra encore quelques semaines. Histoire de “pouvoir répondre à toute sollicitation des six Pôles de compétitivité, dont les besoins sont sensiblement différents”, souligne Pierre-Paul Fares, responsable de l’unité Business Intelligence & Advanced Analytics de NRB. “Un cas d’usage concernant le génome exige de toute évidence une puissance de traitement et une capacité de stockage nettement supérieures à ce que le Pôle Walagrim peut éventuellement demander, par exemple pour un scénario d’analyse de cheptel…”
{kind=link}
Cela implique une sérieuse dose de flexibilité et de dimensionnement dynamique de l’infrastructure. Les porteurs de projets pourront par exemple utiliser les ressources d’un environnement mutualisé ou exiger un environnement privatif, “pour des raisons de confidentialité, de sécurité, de cloisonnement…”
“Les qualités et potentiels intrinsèques de la plate-forme seront à la disposition de tous les futurs clients et utilisateurs”, ajoute encore Pierre-Paul Fares. “Par exemple en termes de minimisation de la latence. La flexibilité dans les ressources et potentiels mis à disposition s’exprimera à un niveau plus élevé.” Il prend l’exemple des outils PMQ (Predictive Maintenance and Quality) d’IBM [solution de suivi en temps réel de multiples sources de données en vue d’anticiper des défaillances d’équipements opérationnels]. Les outils seront accessibles à tous mais “déclinables, voire personnalisables, avec une possibilité d’adapter des algorithmes génériques aux spécificités sectorielles.”
Autre exigence: l’interopérabilité de la plate-forme. “Tout doit être connectable. Tous les outils, tous les jeux de données doivent pouvoir être pris en compte, quels que soient leur type ou leur origine – flux temps réel venant de capteurs, données transactionnelles, statistiques historiques… On doit pouvoir partager et analyser dans un même domaine des données opérationnelles d’entreprises avec des open data venant d’opérateurs publics. Tous les langages d’analyse de données doivent être supportés: Python, R… Et l’infrastructure doit être à même d’intégrer les produits des partenaires, tels que de DataMaestro de Pepite [solution analytique évoluée pour processus manufacturiers].”
Être paré à tout scénario
NRB s’est engagé à ce que le dimensionnement de l’infrastructure du Wallonia Big Data soit effectué de telle sorte à ne jamais tomber à cours de puissance ou d’espace. “Nous aurons toujours 4 ou 8 cas d’usage [lisez: projets ou charges de données] d’avance. L’infrastructure sera scalable afin de pouvoir anticiper de nouvelles requêtes et être toujours en capacité d’accueillir de nouvelles charges, de les héberger et traiter si besoin est. Pour l’instant, les systèmes PureData d’IBM nous permettent de traiter jusqu’à 200 To en parallèle.”
{kind=link}
Qui plus est, l’infrastructure NRB ne sera pas forcément la seule à pouvoir être sollicitée. Pour des projets et cas d’usage exigeant du vrai HPC (high performance computing), un basculement sera opéré vers l’infrastructure du Cenaero. En l’occurrence, le supercalculateur basé à Gosselies (baptisé Zenobe), qui intègre pas moins de 6.000 processeurs (Bull) et annonce une puissance de 201,4 Teraflops. Relire, pour plus de détails, l’article que nous lui avions consacré.
Pourquoi avoir choisi IBM?
“Le choix est purement agnostique”, affirme Jacques Wieczorek, directeur Solutions au département BI/Analytics de NRB. “Nous nous sommes basés sur des études indépendantes, de Gartner, Forrester…, pour déterminer quel fournisseur était le plus avancé, investissait le plus dans le domaine du Big Data.”
{kind=link}
Auparavant, ajoute Pierre-Paul Fares, NRB avait procédé à plusieurs proofs of concept avec des outils open source. “Nous en étions venu à la conclusion qu’une interopérabilité entre les composants destinés à une plate-forme qui doit être robuste, qui doit garantir des performances sans faille et être capable d’industrialisation de processus, n’était pas possible avec des outils open source. Il nous fallait une infrastructure, matérielle et logicielle, qui garantisse une interopérabilité et une gouvernance optimales. La plate-forme la plus avancée était celle d’IBM. C’est en outre la seule qui soit par exemple certifiée 100% en matière de requêtes SQL sur Hadoop…”
Lors de la séance inaugurale de la plate-forme Wallonia Big Data, Jacques Platieau, patron d’IBM Belgique, rappelait pour sa part quelques chiffres qui démontrent toute l’importance du “big data” dans la stratégie de la société: “plus de 30 acquisitions dans le domaine des mégadonnées et de l’analytique [Ndlr: IBM a par exemple racheté récemment The Weather Company et IRIS Analytics], 9 centres dédiés aux solutions analytiques, un tiers du budget de recherche consacré aux données et à l’analytique, et quelque 4.000 brevets sur ce thème.”
Découvrez-nous sur Facebook
Suivez-nous sur Twitter
Retrouvez-nous sur LinkedIn
Régional-IT est affilié au portail d’infos Tribu Médias.